3.5.7. Agregação Espacial
3.5.7.1. Consulta 1
Consulta: Gerar o mapa de Regiões do Brasil a partir do mapa de Unidades Federativas.
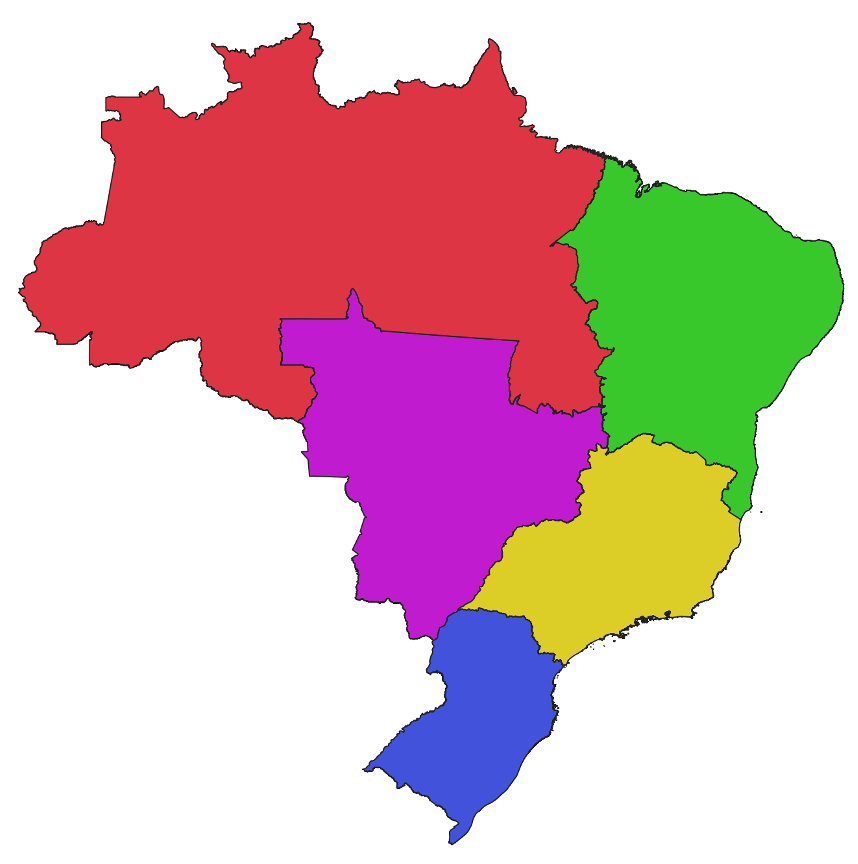
Figura 3.49 - Agregação Espacial - Mapas de Regiões a parir do Mapa de UF.
Solução:
Podemos utilizar a função de agregação ST_Union para computar a geometria formada pela união de todos as geometrias de um grupo definido pela coluna regiao_sig:
CREATE TABLE regioes_brasil AS
SELECT uf.regiao_sig AS sigla,
ST_Union(uf.geom) AS geom
FROM uf
GROUP BY regiao_sig;
Apesar do comando acima funcionar e gerar uma nova tabela chamada regioes_brasil, podemos notar que a estrutura da tabela, isto é, seu esquema, não terá a coluna geom definida com os modificadores de subtipo geométrico e SRID. Verificando a estrutura da tabela:
\d regioes_brasil
Saída:
Table "public.regioes_brasil"
Column | Type | Collation | Nullable | Default
--------+----------------------+-----------+----------+---------
sigla | character varying(2) | | |
geom | geometry | | |
Podemos notar que não foi definido automaticamente o SRID (4674) e o subtipo geométrico da coluna geom. Apesar das geometrias da tabela de entrada serem formadas apenas pelo tipo MultiPolygon, a função ST_Union irá gerar uma geometria do tipo mais simples possível. Nesse caso, teremos linhas com o tipo MultiPolygon ou Polygon. Podemos identificar isso através da seguinte consulta:
SELECT DISTINCT ST_GeometryType(geom) FROM regioes_brasil;
Saída:
st_geometrytype
-----------------
ST_MultiPolygon
ST_Polygon
(2 rows)
Se nossa intenção é obter uma coluna geométrica de um tipo homogeneo, como o subtipo MultiPolygon, poderíamos aplicar a função ST_Multi ao resultado gerado pela função ST_Union, de maneira a garantir que a geometria final da região seja de uma coleção. Também incluiremos um CAST explícito, como mostrado no comando abaixo:
CREATE TABLE regioes_brasil AS
SELECT uf.regiao_sig AS sigla,
ST_Multi( ST_Union(uf.geom) )::geometry(MultiPolygon, 4674) AS geom
FROM uf
GROUP BY regiao_sig;
3.5.7.2. Consulta 2
Consulta: Utilizando os dados dos anos de 2017 e 2018 de focos, apresente uma contagem por bioma.
Solução:
A primeira solução que vamos dar é construir uma consulta envolvendo as tabelas focos e biomas como mostrado abaixo:
SELECT biomas.bioma AS bioma,
COUNT(*) AS total_focos
FROM focos,
biomas
WHERE ST_Contains(biomas.geom, focos.geom)
GROUP BY biomas.bioma;
Resultado:
bioma | total_focos
----------------+-------------
Amazônia | 2350680
Caatinga | 252185
Cerrado | 1677410
Mata Atlântica | 314255
Pampa | 14015
Pantanal | 96295
(6 rows)
No meu sistema, a consulta acima é executada da seguinte forma:
EXPLAIN ANALYZE
SELECT biomas.bioma AS bioma,
COUNT(*) AS total_focos
FROM focos,
biomas
WHERE ST_Contains(biomas.geom, focos.geom)
GROUP BY biomas.bioma;
Resultado:
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=920634.25..920634.31 rows=6 width=17) (actual time=97122.996..97122.999 rows=6 loops=1)
Group Key: biomas.bioma
Batches: 1 Memory Usage: 24kB
-> Nested Loop (cost=147.82..780413.91 rows=28044069 width=9) (actual time=675.390..95716.016 rows=4704840 loops=1)
-> Seq Scan on biomas (cost=0.00..1.06 rows=6 width=3267257) (actual time=0.066..0.074 rows=6 loops=1)
-> Bitmap Heap Scan on focos (cost=147.82..130064.10 rows=471 width=32) (actual time=340.626..15829.862 rows=784140 loops=6)
Filter: st_contains(biomas.geom, geom)
Rows Removed by Filter: 1173152
Heap Blocks: exact=217942
-> Bitmap Index Scan on focos_geom_idx (cost=0.00..147.70 rows=4705 width=0) (actual time=233.648..233.648 rows=1957292 loops=6)
Index Cond: (geom @ biomas.geom)
Planning Time: 1.039 ms
JIT:
Functions: 10
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 3.443 ms, Inlining 30.710 ms, Optimization 122.044 ms, Emission 34.748 ms, Total 190.945 ms
Execution Time: 97131.554 ms
(17 rows)
Time: 97133.166 ms (01:37.133)
Ou seja, essa consulta é executada em aproximadamente 01 minuto e 37 segundos. Você saberia explicar onde essa consulta está gastando a maior parte do tempo?
Vamos agora tentar uma estratégia diferente, criando uma nova tabela com os biomas onde os polígonos são particionados em um conjunto de polígonos com um número menor de vértices, digamos 40:
CREATE TABLE biomas_subdividido AS
SELECT gid,
bioma,
ST_SubDivide(geom, 40)::geometry(POLYGON, 4674) as geom
FROM biomas;
CREATE INDEX biomas_subdividido_geom_idx ON biomas_subdividido USING GIST (geom);
Agora, vamos verificar como a mesma consulta é realizada usando essa nova tabela:
EXPLAIN ANALYZE
SELECT biomas.bioma AS bioma,
COUNT(*) AS total_focos
FROM focos,
biomas_subdividido AS biomas
WHERE ST_Contains(biomas.geom, focos.geom)
GROUP BY biomas.bioma;
Resultado:
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=3184627193.25..3184796844.98 rows=6 width=18) (actual time=5175.062..5421.178 rows=6 loops=1)
Group Key: biomas.bioma
-> Gather Merge (cost=3184627193.25..3184796844.86 rows=12 width=18) (actual time=5154.357..5421.154 rows=18 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial GroupAggregate (cost=3184626193.23..3184795843.45 rows=6 width=18) (actual time=5027.934..5198.022 rows=6 loops=3)
Group Key: biomas.bioma
-> Sort (cost=3184626193.23..3184682743.28 rows=22620022 width=10) (actual time=4831.571..5068.800 rows=1568280 loops=3)
Sort Key: biomas.bioma
Sort Method: external merge Disk: 28376kB
Worker 0: Sort Method: external merge Disk: 32792kB
Worker 1: Sort Method: external merge Disk: 29344kB
-> Nested Loop (cost=0.41..3181089883.47 rows=22620022 width=10) (actual time=256.340..4276.527 rows=1568280 loops=3)
-> Parallel Seq Scan on biomas_subdividido biomas (cost=0.00..3967.23 rows=27023 width=415) (actual time=0.022..7.081 rows=21618 loops=3)
-> Index Scan using focos_geom_idx on focos (cost=0.41..117713.01 rows=471 width=32) (actual time=0.034..0.177 rows=73 loops=64855)
Index Cond: (geom @ biomas.geom)
Filter: st_contains(biomas.geom, geom)
Rows Removed by Filter: 0
Planning Time: 4.153 ms
JIT:
Functions: 36
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 7.451 ms, Inlining 199.374 ms, Optimization 358.225 ms, Emission 202.490 ms, Total 767.540 ms
Execution Time: 5429.893 ms
(24 rows)
Time: 5434.675 ms (00:05.435)
Repare que essa consulta é executada em pouco mais de 5 segundos! Você saberia dizer por que essa tabela de biomas com um número maior de linhas produz um resultado melhor do que a primeira solução que continha apenas 6 linhas?
Nota
As consultas desta seção também são conhecidas por Spatial Aggregation.