2.22. Importando e Exportando Dados
O PostgreSQL fornece um comando para uso via SQL chamado COPY que permite mover dados de arquivos para tabelas do banco de dados e vice-versa. Este comando permite lidar com arquivos texto, CSV e binários. Nesta seção vamos explorar esse comando de importação e exportação de dados, que é usado pelo meta-comando \copy do aplicativo psql bem como pelo pgAdmin.
2.22.1. Importando Arquivos CSV
Considere o arquivo CSV mostrado abaixo, que contém dados sobre focos de queimada na vegetação localizados no município de São Félix do Xingu, no Pará, no dia 01 de setembro de 2022:
id,lat,lon,data_hora_gmt,satelite,municipio,estado,pais,bioma,frp
d83c2dd8-d113-3ec2-9be7-1cdbbd41303a,-9.488684,-51.500988,2022-09-01 01:20:34,NOAA-18D,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,
a2e04670-bb02-3829-a2b7-748fba959dfc,-9.490747,-51.515862,2022-09-01 01:20:34,NOAA-18D,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,
5f9d2693-8509-3762-81d9-1ffb360fa63c,-5.266089,-50.923878,2022-09-01 01:21:42,NOAA-18D,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,
22f47f02-4c63-3908-bb94-bfd6c6cceb17,-7.05389,-52.22334,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,9.5
07ac46a3-6401-36e0-807b-83784822b926,-5.22987,-50.79867,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,16.5
6818cb51-99d5-3988-ba33-7902e541db82,-5.23125,-50.80866,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,6.3
15277316-02fe-3f55-9716-fe04d1c6bb7f,-5.27069,-50.88464,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,5.2
57c8f78f-f307-39f0-aeb1-3445e944d509,-5.27209,-50.89471,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,7.9
dd9c98fe-7aa9-39bc-90bf-da044dbd7269,-5.28016,-50.88336,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,6
4cac4be6-96fa-3062-8d8e-935c7a052021,-5.28157,-50.89342,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,8.8
832aa480-0954-39dc-a7c0-4913c015be0b,-5.51342,-50.99733,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,5.6
21dca10b-605a-3741-b076-21f930b08c81,-6.05429,-51.82471,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,9.9
4264fb99-6e59-3a25-b70e-d438091449c9,-6.12482,-52.73333,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,8.9
990a0d2d-557a-33fd-a35a-da7102aa0576,-6.63889,-52.46607,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,5.8
ef84c71d-9b19-3816-8b7b-82fc574fc484,-6.82739,-52.859,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,8.3
Nota
Os dados apresentados neste arquivo foram extraídos no Portal de Dados Abertos do Programa Queimadas.
Nota
O arquivo CSV completo com dados de focos de calor para o dia 01 de setembro de 2022 pode ser baixado do seguinte linl focos_abertos_24h_20220901.csv.
Repare que esse arquivo possui uma primeira linha com um cabeçalho, indicando as colunas presentes:
id,lat,lon,data_hora_gmt,satelite,municipio,estado,pais,bioma,frp
Os campos encontram-se separados pelo caractere ,:
60e9d84c-b96e-3616-8433-5c4c979c5054,-9.45669,-51.60427,2022-09-01 01:34:00,TERRA_M-M,SÃO FÉLIX DO XINGU,PARÁ,Brasil,Amazônia,7.2
Para importar esse arquivo para o banco de dados usando o comando COPY, primeiro devemos criar uma tabela capaz de armazenar esses dados:
CREATE TABLE foco
(
id UUID,
lat DOUBLE PRECISION,
lon DOUBLE PRECISION,
data_hora_gmt TIMESTAMP WITHOUT TIME ZONE,
satelite VARCHAR(100),
municipio VARCHAR(100),
estado VARCHAR(100),
pais VARCHAR(100),
bioma VARCHAR(100),
frp DOUBLE PRECISION
);
Nota
Repare que não incluímos restrições na definição da tabela acima.
Para copiar o arquivo acima para a nova tabela criada, podemos utilizar o comando SQL COPY indicando na cláusula FROM o caminho completo para que o servidor encontre o arquivo de dados, como mostrado abaixo:
COPY foco(id, lat, lon, data_hora_gmt, satelite, municipio, estado, pais, bioma, frp)
FROM '/data/focos-sao-felix-do-xingu-20220901.csv'
WITH (DELIMITER ',', FORMAT CSV, HEADER true);
COPY 4122
No comando acima o nome da tabela para onde importaremos o dado é especificado logo após a palavra-chave COPY. Se a tabela possuir as mesmas colunas do arquivo CSV, então podemos omitir a lista de colunas, caso contrário, as colunas para as quais copiaremos os dados deverão aperecer entre parênteses, como feito no exemplo acima. O caminho do arquivo CSV é colocado logo após a palavra-chave FROM. Ao final do comando podemos especificar algumas opções, tais como: o delimitador de valores usado no arquivo (,), o formato do arquivo (CSV) e a presença de uma linha de cabeçalho no início do arquivo (HEADER).
Se o comando acima for bem sucedido, você receberá uma mensagem indicando que 4122 linhas foram copiadas para a tabela foco.
Nota
O exemplo acima também poderia ser realizado sem especificar as colunas da tabela de destino:
COPY foco
FROM '/data/focos-sao-felix-do-xingu-20220901.csv'
WITH (DELIMITER ',', FORMAT CSV, HEADER true);
2.22.1.1. Usando o Meta-comando \copy
Um detalhe importante sobre o comando COPY é que o arquivo de dados informado será lido pelo servidor PostgreSQL e, portanto, deve estar em um caminho acessível por ele. Isso significa que o arquivo precisa estar num sistema de arquivos acessível pelo servidor e que o usuário que executa o processo do servidor PostgreSQL precisará ter privilégios de leitura tanto no diretório quanto no arquivo de dados. Para relaxar essa restrição, as aplicações clientes, como o psql e o pgAdmin, utilizam uma variante desse comando que realiza a leitura e escrita para a entrada/saída padrão (COPY FROM STDIN ou COPY TO STDOUT).
No caso do psql, ele fornece um meta-comando chamado \copy que pode ser usado de maneira análoga ao comando COPY. A diferença essencial é que o \copy realiza a leitura do arquivo no lado cliente, isto é, onde o psql é executado, e este é que de fato envia os dados pela rede de comunicação com o servidor PostgreSQL usando nos bastidores o comando COPY FROM STDIN. Portanto, o exemplo da seção anterior poderia ser construído com o psql da seguinte forma:
\copy foco FROM '/data/focos-sao-felix-do-xingu-20220901.csv' WITH (DELIMITER ',', FORMAT CSV, HEADER);
Dica
Uma forma simples de limpar o conteúdo de uma tabela é usar o comando TRUNCATE TABLE, como mostrado abaixo:
TRUNCATE TABLE foco;
Dica
Para saber mais sobre o comando COPY, consulte o manual do PostgreSQL na Seção COPY.
Dica
Para saber mais sobre o meta-comando \copy, veja o manual do psql.
2.22.1.2. Importando Dados pelo pgAdmin
Pela interface gráfica do pgAdmin é possível importar arquivos CSV. Ao selecionar a tabela para a qual se deseja copiar os dados, selecione o menu Import/Export Data..., como mostrado na figura abaixo:
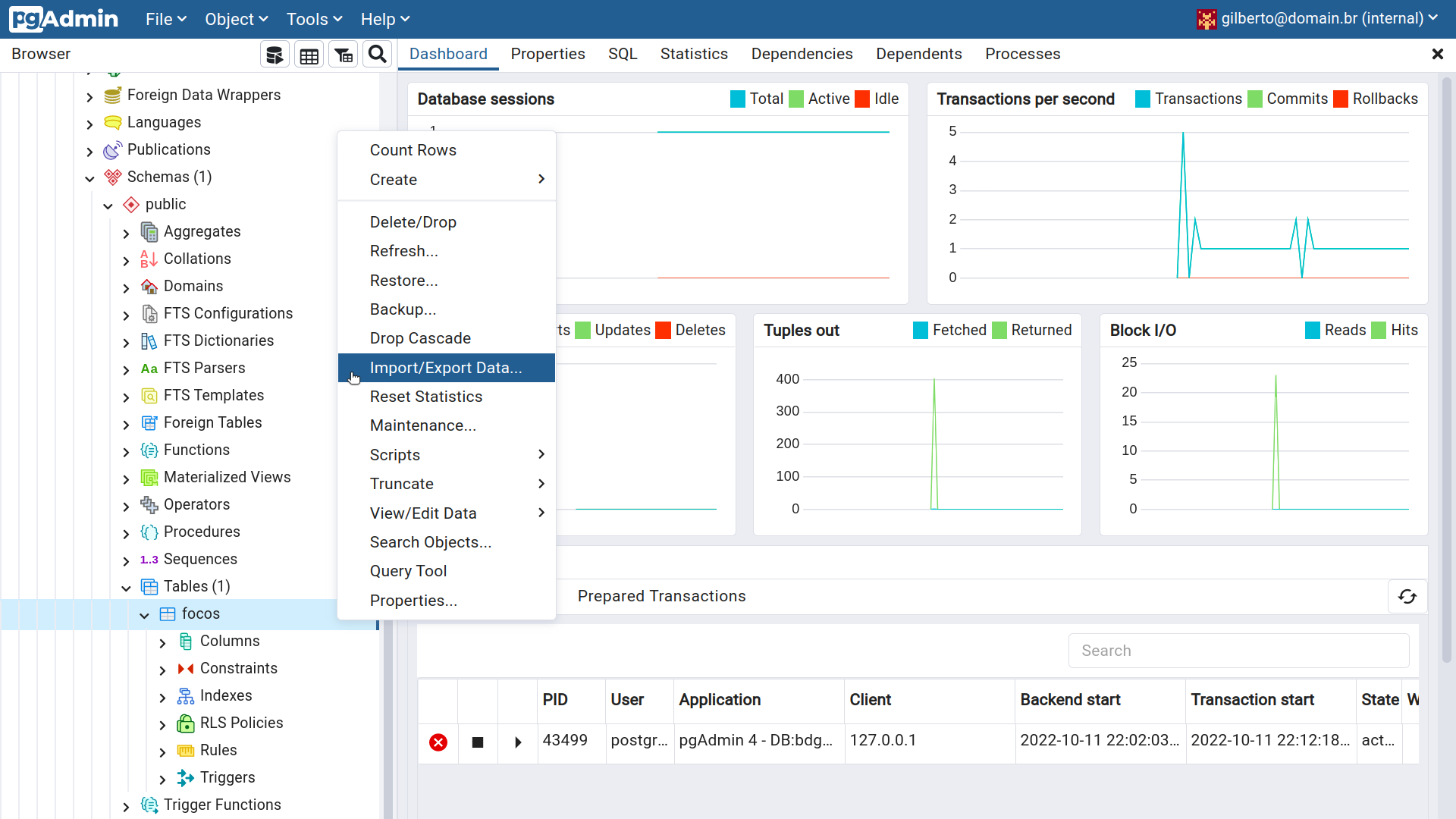
Figura 2.22 - Importando dados para a tabela focos
Na janela aberta, com a opção Import selecionada, devemos indicar o arquivo a ser carregado:
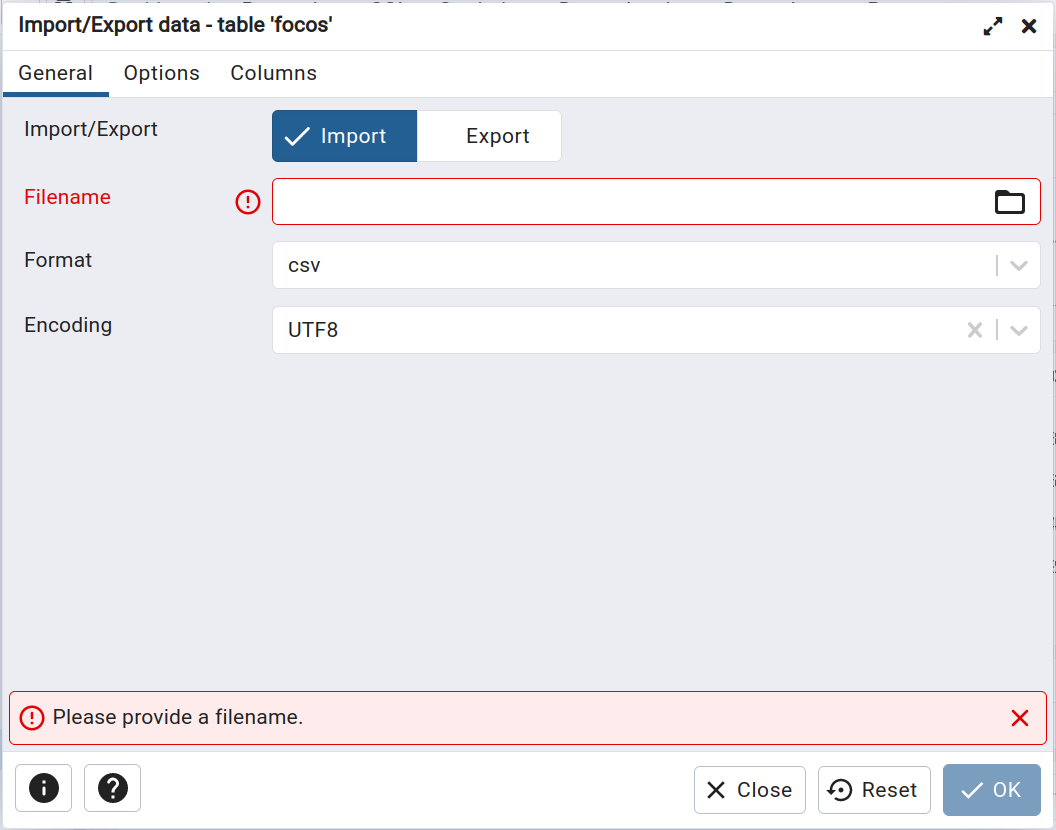
Figura 2.23 - Importando dados para a tabela focos
O arquivo pode ser indicado de diversas formas. Uma delas consiste em fazer o upload do arquivo:
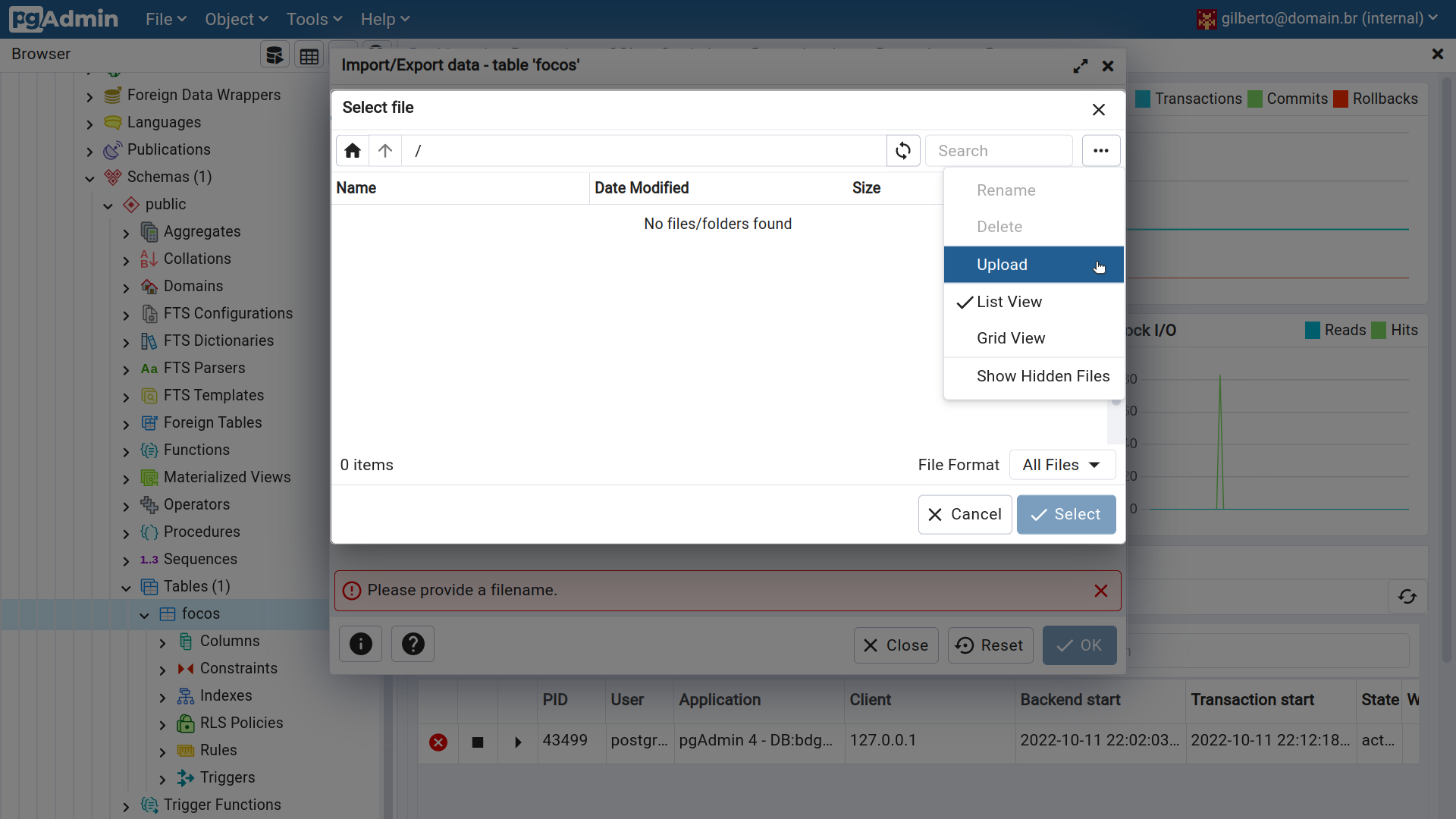
Figura 2.24 - Importando dados para a tabela focos
Figura 2.25 - Importando dados para a tabela focos
Figura 2.26 - Importando dados para a tabela focos
Figura 2.27 - Importando dados para a tabela focos
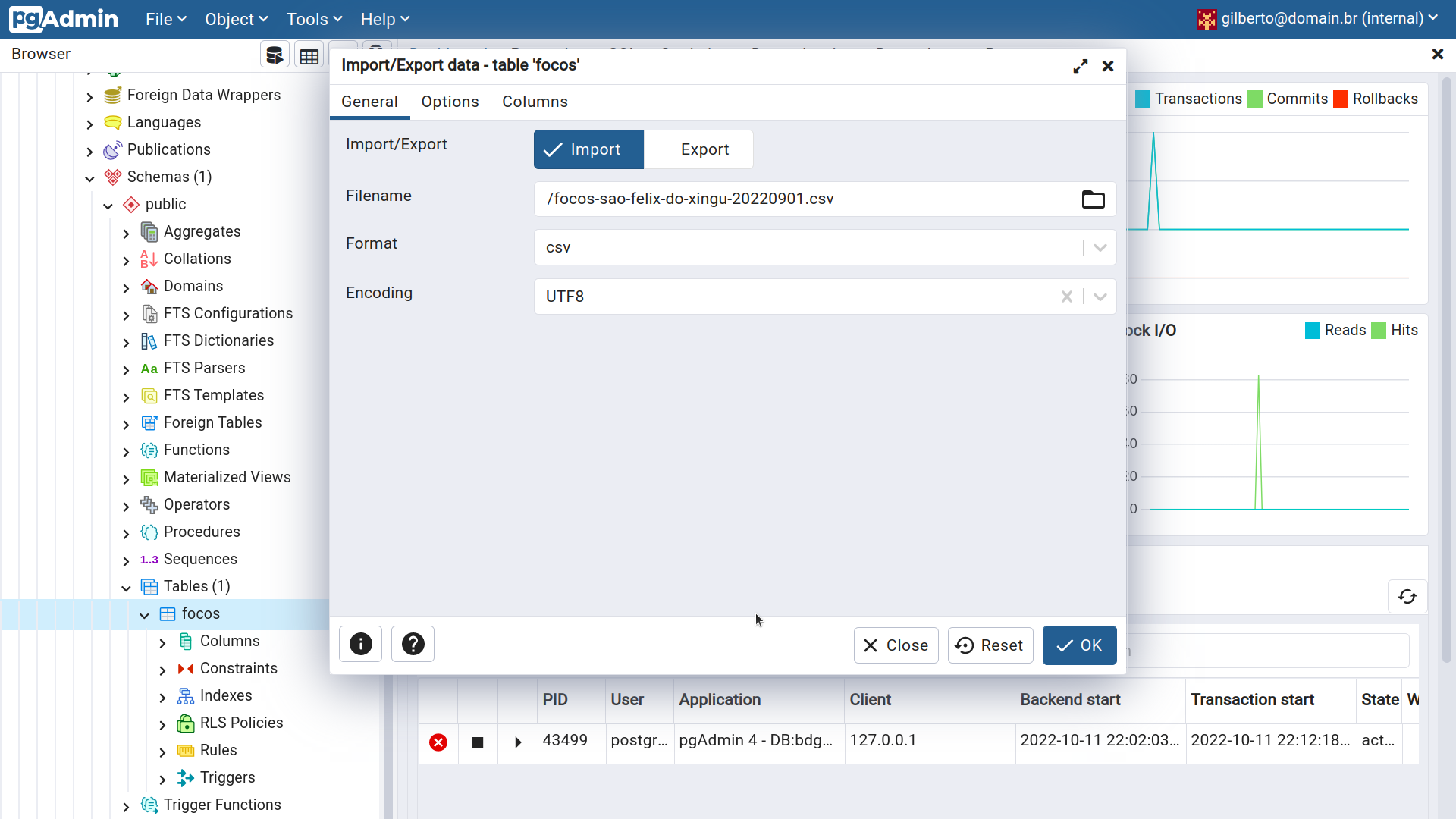
Figura 2.28 - Importando dados para a tabela focos
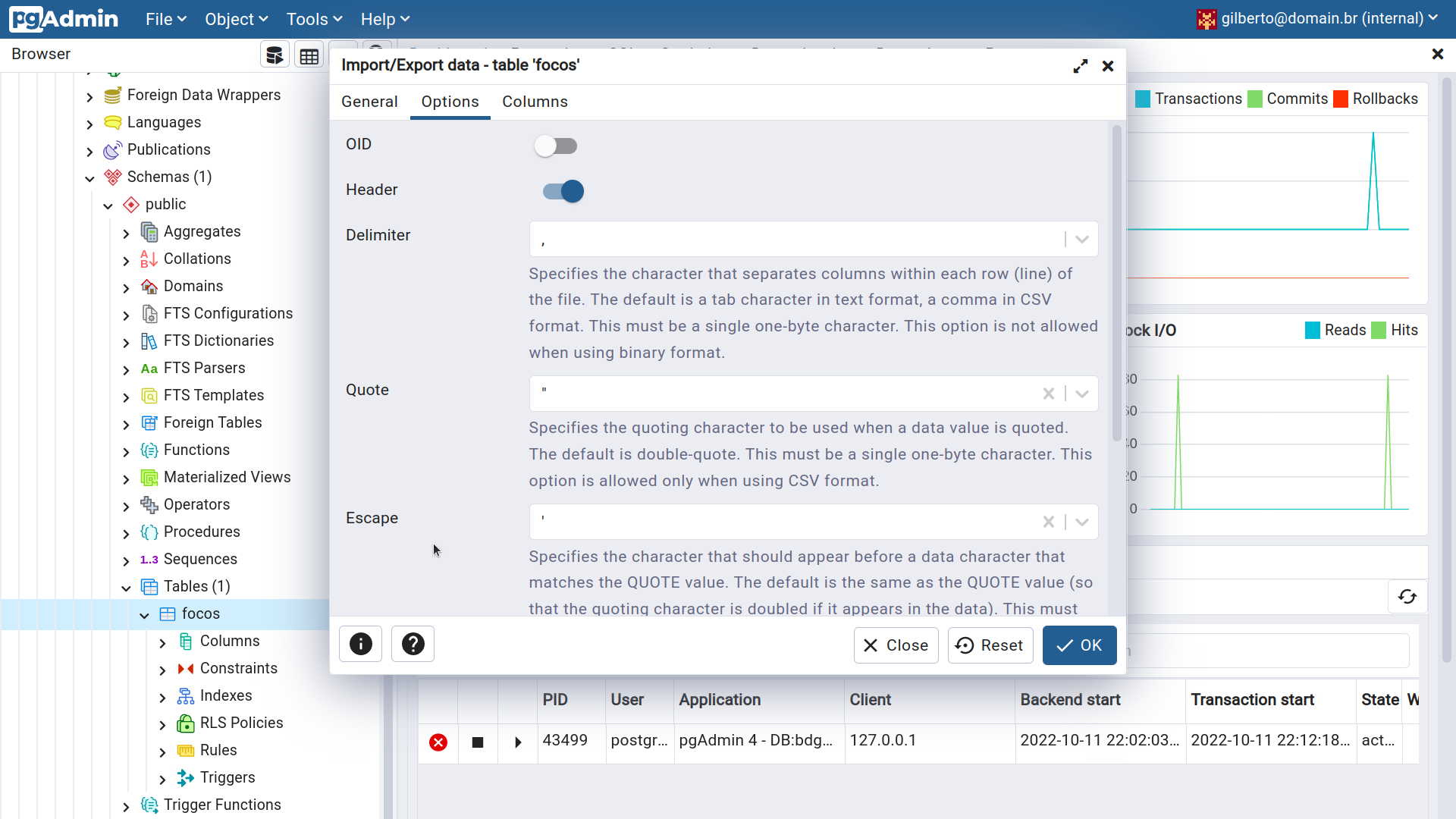
Figura 2.29 - Importando dados para a tabela focos
Figura 2.30 - Importando dados para a tabela focos
2.22.2. Exportando para Arquivos CSV
Vamos usar o meta-comando \copy para exportar os dados da tabela foco para um arquivo denominado /data/foco-all.csv, onde a primeira linha será de cabeçalho e os valores em cada uma das linhas exportadas serão separados por ,:
\copy foco TO '/data/foco-all.csv' WITH (DELIMITER ',', FORMAT CSV, HEADER true);
Resultado:
COPY 4122
Podemos também exportar o resultado de uma consulta:
\copy (SELECT id, lat, lon FROM foco WHERE satelite = 'TERRA_M-T') TO '/data/foco-light.csv' WITH (DELIMITER ',', FORMAT CSV, HEADER true);
Resultado:
COPY 36
2.22.3. Exercícios
Exercício 1. Importe os dados do arquivo municipios-brasil.csv para uma tabela denominada municipio. Este arquivo, obtido no site do IBGE, contém uma lista dos código de munícipios brasileiros e o respectivo nome.
Solução:
Vamos criar uma tabela chamada municipio compatível com as linhas do arquivo municipios-brasil.csv:
CREATE TABLE municipio
(
id CHAR(7) PRIMARY KEY NOT NULL,
nome VARCHAR(40) NOT NULL
);
Em seguida, vamos importar o arquivo:
\copy municipio FROM '/data/municipios-brasil.csv' WITH (DELIMITER ';', FORMAT CSV, HEADER false);
Resultado:
COPY 5570
Exercício 2. Importe os dados do arquivo ipeadata-homicidios.csv para uma tabela denominada homicidio_tmp. Este arquivo, obtido no site do IPEA, contém uma série histórica do número de homicídios nos munícipios brasileiros.
Solução:
Vamos criar uma tabela chamada homicidio_tmp compatível com as linhas do arquivo ipeadata-homicidios.csv:
CREATE TABLE homicidio_tmp
(
uf CHAR(2),
id CHAR(7),
nome VARCHAR(40),
a1980 INTEGER,
a1981 INTEGER,
a1982 INTEGER,
a1983 INTEGER,
a1984 INTEGER,
a1985 INTEGER,
a1986 INTEGER,
a1987 INTEGER,
a1988 INTEGER,
a1989 INTEGER,
a1990 INTEGER,
a1991 INTEGER,
a1992 INTEGER,
a1993 INTEGER,
a1994 INTEGER,
a1995 INTEGER,
a1996 INTEGER,
a1997 INTEGER,
a1998 INTEGER,
a1999 INTEGER,
a2000 INTEGER,
a2001 INTEGER,
a2002 INTEGER,
a2003 INTEGER,
a2004 INTEGER,
a2005 INTEGER,
a2006 INTEGER,
a2007 INTEGER,
a2008 INTEGER,
a2009 INTEGER,
a2010 INTEGER,
a2011 INTEGER,
a2012 INTEGER,
a2013 INTEGER,
a2014 INTEGER,
a2015 INTEGER,
a2016 INTEGER,
a2017 INTEGER,
a2018 INTEGER,
a2019 INTEGER,
a2020 INTEGER
);
Em seguida, vamos importar o arquivo:
\copy homicidio_tmp FROM '/data/ipeadata-homicidios.csv' WITH (DELIMITER ',', FORMAT CSV, HEADER true);
Resultado:
COPY 5570
Exercício 3. Crie uma nova tabela denominada homicidio com o esquema mostrado abaixo e preencha ela com os dados provenientes da tabela homicidio_tmp:
nome tabela: homicidio |
||
|---|---|---|
colunas |
tipo de dados |
modificadores |
id |
texto de tamanho fixo |
tamanho fixo de 07 caracteres, NOT NULL,
Chave Estrangeira associada à tabela |
ano |
número inteiro |
faixa de valores entre 1980 e 2020, NOT NULL |
num_homicidios |
número inteiro |
NOT NULL |
Solução:
Vamos criar a tabela homicidio através da seguinte definição:
CREATE TABLE homicidio
(
id CHAR(7) NOT NULL REFERENCES municipio(id)
ON DELETE NO ACTION
ON UPDATE CASCADE,
ano INTEGER NOT NULL CHECK (ano >= 1980 AND ano <= 2020),
num_homicidios INTEGER NOT NULL
);
Em seguida, vamos inserir dados nessa tabela a partir da tabela temporária criada. Para isso poderíamos utilizar vários comandos como o mostrado abaixo:
INSERT INTO homicidio (SELECT id, 1980, a1980 FROM homicidio_tmp WHERE a1980 IS NOT NULL);
No entanto, teríamos que escrever uma linha dessa para cada coluna da tabela homicidio_tmp. Uma maneira de fazermos isso facilmente é escrever um pequeno programa em Python como mostrado abaixo:
SQL = 'INSERT INTO homicidio (SELECT id, {0}, a{0} FROM homicidio_tmp WHERE a{0} IS NOT NULL);'
for i in range (1980, 2021):
print(SQL.format(i))
Esse programa irá gerar todos os comandos necessários:
INSERT INTO homicidio (SELECT id, 1980, a1980 FROM homicidio_tmp WHERE a1980 IS NOT NULL);
...
INSERT INTO homicidio (SELECT id, 2020, a2020 FROM homicidio_tmp WHERE a2020 IS NOT NULL);
Ao término da preparação dessa tabela, você deverá ter \(119791\) linhas na tabela homicidio:
SELECT COUNT(*) AS total_homicidios FROM homicidio;
total_homicidios
------------------
119791
(1 row)
Exercício 4. Importe os dados do arquivo ipeadata-populacao-2010.csv para uma tabela denominada populacao_2010_tmp. Este arquivo, obtido no site do IPEA, contém dados populacionais dos munícipios brasileiros para o ano de 2010.
Solução:
Vamos criar uma tabela chamada populacao_2010_tmp compatível com as linhas do arquivo ipeadata-populacao-2010.csv:
CREATE TABLE populacao_2010_tmp
(
uf CHAR(2),
id CHAR(7),
nome VARCHAR(40),
urbana_feminina INTEGER,
rural_feminina INTEGER,
urbana_masculina INTEGER,
rural_masculina INTEGER,
urbana INTEGER,
rural INTEGER,
feminia INTEGER,
masculina INTEGER,
total INTEGER
);
Em seguida, vamos importar o arquivo:
\copy populacao_2010_tmp FROM '/data/ipeadata-populacao-2010.csv' WITH (DELIMITER ';', FORMAT CSV, HEADER true);
Resultado:
COPY 5596
Nota
Ao importar o arquivo acima, verifique se existe alguma linha na nova tabela populacao_2010_tmp que não tenha um id correspondente na tabela municipio:
SELECT COUNT(*) FROM populacao_2010_tmp WHERE id NOT IN (SELECT id FROM municipio);
Resultado:
count
-------
26
(1 row)
Logo, temos 26 linhas sem correspondência na tabela municipio. Vamos exercitar o comando DELETE removendo essas linhas sem correspondência:
DELETE FROM populacao_2010_tmp WHERE id NOT IN (SELECT id FROM municipio);
Resultado:
DELETE 26
Exercício 5. Assim como no exercício anterior, importe os dados dos seguintes arquivos:
Nota
Os dados acima podem ser obtidos no site do IPEA.
Exercício 6. Crie uma nova tabela denominada populacao com o esquema mostrado abaixo e preencha suas linhas com os dados provenientes das tabelas populacao_2010_tmp e demais tabelas criadas no exercício 5:
nome tabela: populacao |
||
|---|---|---|
colunas |
tipo de dados |
modificadores |
id |
texto de tamanho fixo |
tamanho fixo de 07 caracteres, NOT NULL,
Chave Estrangeira associada à tabela |
ano |
número inteiro |
faixa de valores entre 1960 e 2010, NOT NULL |
urbana_feminina |
número inteiro |
NOT NULL |
rural_feminina |
número inteiro |
NOT NULL |
urbana_masculina |
número inteiro |
NOT NULL |
rural_masculina |
número inteiro |
NOT NULL |